A layman's guide to Large Language Models

Hey there! My name is shreshtha, I use data to solve the problems around me. I am an advocate for open education. I am extremely passionate about free software, using data science for social good and making the world of tech more accessible for the people of marginalised community. Join me here as I write about my experiences around tech and hopefully, you just might find something interesting!
If you've been anywhere on the internet lately, chances are you've been swept up in the whirlwind of OpenAI, particularly its brainchild, ChatGPT. But what exactly is ChatGPT, or any large language model for that matter? In this article, I attempt to uncover the working behind these digital marvels.
Large language models are built upon deep neural networks, learning to predict the next word in a sequence by analyzing the context provided.
In the world of science and technology, language models have become indispensable aids for research. There have been several instance of people building succesful businesses with the help of these models. But their impact reaches far beyond business or science. They've elevated people's culinary skills, sparked creativity in poetry, and even helped write code. As their influence continues to endure, there's a growing necessity for us all to become adept at utilizing these models.
How does an LLM "think"?
If you have had the chance to experiment with ChatGPT, you'd likely wondered about it's capability of generating text to the questions provided. But how does it really work? Does it have access to an internet directory where it can go and look for answer? Well the yes and No. The base language models are often trained on data that is a representative of the internet. Once it has analyzed the patterns just enough to know what comes after the other, it can start predicting things. Let us look at an example to clarify things a little

In the given illustration, the model is provided with the input the sky is and based on the training data that it was trained on, it generates the probabilities of tokens which are likely to follow the given sequence. Based on the computation done, it predicts that the most likely token or word to follow the phrase 'the sky is' is blue and hence it gives the result. It is also worthwile to mention that sometimes it comes across a phrase a sentence that it really hasnt seen before or seen a limited number of times and sometimes it generates a response that makes no sense to humans or one that it is factually incorrect and that phenomenon is called hallucination. Unfortunately, besides manual testing or human intervention, it can be tricky to identify whether the response is factually correct or the model is hallucinating hence the responses from these models should always be taken with a grain of salt
Contrary to popular belief, large language models aren't sentient beings. They lack consciousness and independent thought. Instead, they're meticulously crafted tools, honed to analyze and generate text based on statistical patterns
Even though language models aren't exactly thinking machines, they bring some pretty neat advantages to the table. With a bit of clever thinking, you can save yourself a ton of time and hassle in the long haul. Just look at tools like Research GPT—they're like your own personal research assistant, summarizing papers, videos, and docs, and pulling out all the important information from a mountain of text. If you're in a field like law where you're constantly wading through pages of legalese, this can save you a considerable amount of time and resources which could be better utilized elsewhere.
Due to the advancements in the current research, it is now possible to finetune language models to your specific need such as supporting local usage, turning off data sharing and fine tuning them on custom datasets. But in order to do that, it is crucial to understand how these models are built
How are LLMS built?
At its core , almost all of the leading propritery and open source language model can be summarized as two files.

A training file which contains a compressed chunk of the entire internet. That sounds a bit too unrealistic? How can the entire internet be contained in one single text file?
Well, The training data isn't a literal copy of the internet; rather, it's a collection of text fragments or tokens extracted from various online sources. These tokens are then compressed using sophisticated algorithms and encoding techniques, much like how a zip file reduces the size of a document. However, even with compression, processing this data requires special hardware—GPUs—which are run in parallel to train language models like ChatGPT.
These specialized hardward require significiant economical investment and has a considerable carbon footprint as well.As a matter of fact, the cost of training ChatGPT was estimated to be around 10 million dollars by the ceo of OpenAI, Sam Altman!
The latest version of ChaptGPT, GPT4 is rumored to be trained on trillions of tokens! it simply means that it had a lot more time and data to learn from as compared to its predeccesors making it a lot more powerfu
The script file is a file that runs the code on the training data. More often than not, language models are built using deep learning technqiues such as neural networks. While the exact architecutre of the network differs by models, there are some characteristics which stays the same.
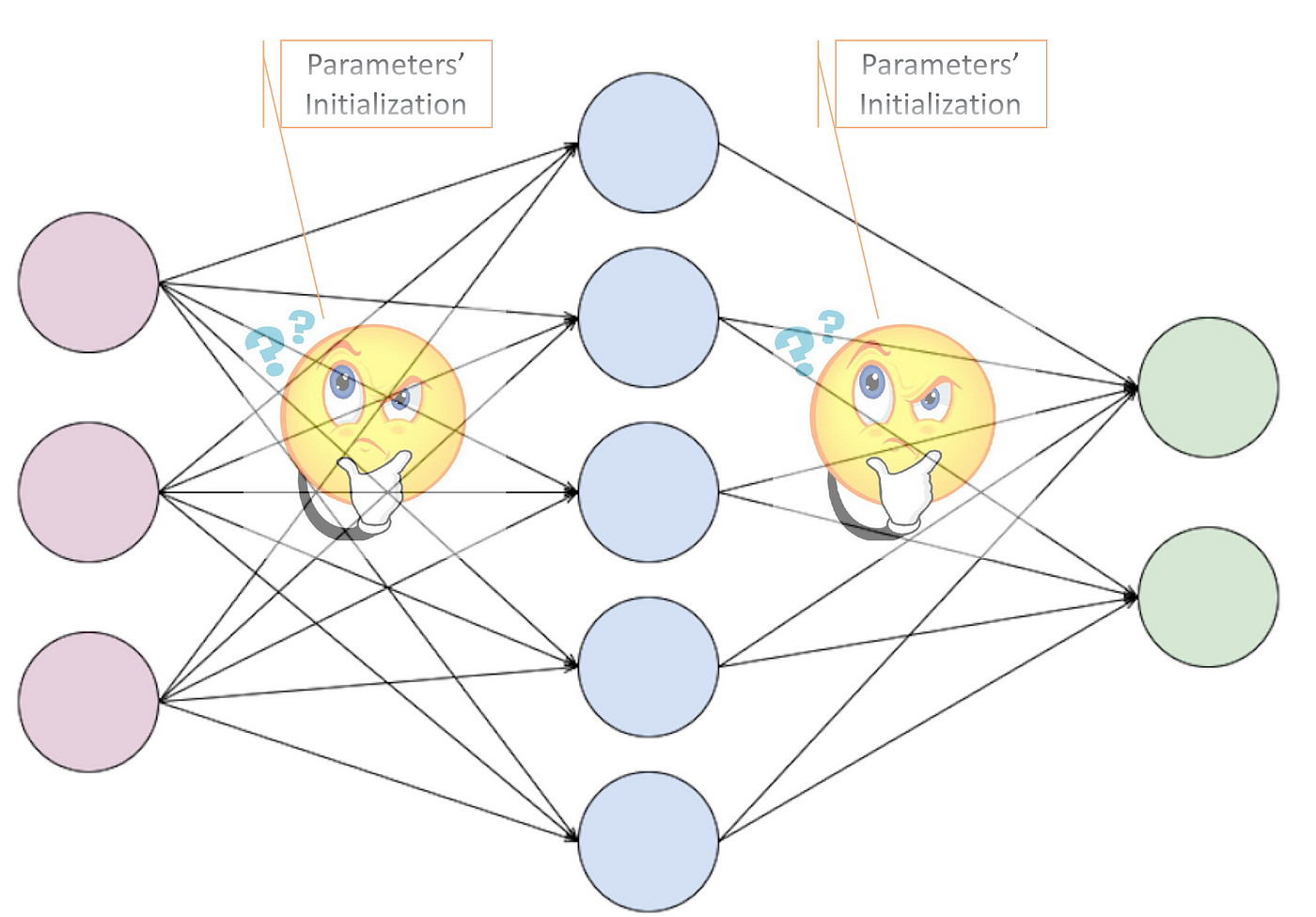
Each network has an input layer, a hidden layer containing weights and biases and parameters and an output layer.
These become super important as they help determine how and what will our models predict
Weights represent the strength of connections between neurons, determining how much influence one neuron has on the next. Biases act as additional parameters that help the model adapt and learn from the data. These are known as parameters which can be tuned in to modify the direction and structure of parameters
During training, the network initializes and updates these weights and biases over multiple iterations, or epochs. This process allows the neural network to learn from the training data and improve its predictive capabilities.
GPT4,the latest version of chatGPT on the time of writing this article consists of 1.7 trillion parameters and is rumored to be trained on tokens in the range of trillions.
A language model with more paramteres usually means that it is a lot more sophasticated
Currently GPT4 has been excelling at all the benchmarks established by researchers. However, little is known about the architecutre or the weights and biases or the data that it was trained on limiting the accesbility of the model
Researchers all around the world have been working hard and developing their own versions of open source language models and giving out the info about how their models are built, the training data that was being used and the weights and biases which were used. This makes research a lot more accesible and we can even customize the models to suit our usecases better
Using these two files, one could theoratically, create their own language model. However, due to the significant cost being the barrier to entry, most of the times it is simply not possible or needed to do so. A lot of the people have already worked on this problem to create base models, we can use these and some training data to tailor the model to our need. In order to do so, let us understand what is finetuning and what are some popular finetuning techniques
How are these models trained?
The training of these models can be roughly divided into two stages. One preliminary pre training stage and a subsequent stage called fine-tuning stage
During the pre-training stage, since the model is trained on a vast corpus of internet data, the process can take weeks to months or even years.
Moreover, The internet as we know it, is not a safe place. It is built by humans for humans and inherits a lot of biases that we as humans unconciuously suffer from. When the model learns these biases, it becomes unreliable as a source of accurate information. Moreover, the internet is replete with noise and irrelevant content, which can hinder rather than enhance the model's predictive accuracy.
This is where fine-tuning comes into play. Fine-tuning is an additional but crucial step in the training process, wherein researchers refine the model using a smaller, curated dataset, often with human oversight. It serves as a vital safety mechanism, allowing researchers to introduce safeguards and mitigate biases inherent in the pre-trained model.
Since the data used to fine tune a model is relatively smaller, we as end users can use this process to customize the language models to serve us better
For instance, fine-tuning a model on US law and labor statistics can enhance its performance in legal contexts, as it becomes more specialized and attuned to the nuances of legal language and concepts.

Fine tuning LLM techniques

Fine-tuning has been a topic of interest among researchers, opening up exciting new possibilities for specialization. However, fine-tuning can be very troublesome, especially when you're dealing with the whole parameter matrix – that's every weight and bias in the model.
Techniques such as LoRA and QLora are making the process of finetuning more accesible by reducing the need for computing power. Using these techniques, it might even be possible to fine-tune models right on your local machine
Let us look at the essence of LoRA and QLoRA
LoRA
LoRA belongs to a category of fine-tuning techniques known as Parameter Efficient Fine Tuning, which aim to reduce the number of trainable parameters. LoRA, short for Low Rank Adaptation Matrix, achieves this by introducing a set of smaller, low-rank matrices that are decompositions of the original weight matrix.

To understand LoRA, let's first delve into matrix multiplication using the provided illustration. In this illustration, we have two matrices, A and B, and their multiplication results in a matrix AB. According to the rule of matrix multiplication:
$$[ A_{m \times n} \times B_{n \times m} = C_{m \times m} ]$$
This rule states that the number of rows in one matrix should be equal to the number of columns in the other matrix, and the resultant matrix C has m rows and m columns.
We can use this same principle to breakdown the weight matrix into two smaller matrices and thus, instead of using a big matrix during backpropagation, we update smaller matrices which saves us a lot of computation. For E.g, if the weight matrice given to us contains 125 rows and 105 columns, then we can break it down in two matrices with one matrice containing 125 rows and 10 columns and 10 rows and 105 columns.
One misconception that a lot of people with LoRA is that we are not working with all the weights, that is however not true. We do utilize all of the weight matrices but we use a small subset of them at a time instead of a big one using the property of matrix multiplication!
QLoRA
QLoRA is also a part of the Parameter Efficient Fine-tuning technique, which relies heavily on the concept of Quantization. Parameters of a language model are usually represented as a 16 bit number ( ranging from 0 through 65,535) where 1 bit can take only two values 0 or 1. As one can imagine, these numbers are of very high precision, which also means the memory required is more. We use quantization to reduced this 16 bit high precision number to a 4 bit number.
Quantization is a popular technique in computer science which is used to convert continuous values (values which can take on infinite numbers) to discreet values (values which can take finite numbers). As a matter of fact, quantization forms the base for digital communication and it is how the signals are transmitted.
What QLoRA does is assume a normal distribution for the 16 bit number. Normal distribution is a type of distribution which assumes that the values followed by a number are symmetrical and mostly centered around mean. Most natural phenomenons follow normal distribution

Assuming normal distribution, it finds the probability of where the 4 bit number lies on the curve of the 16 bit number and quantizes it. Thus it reduces memory requirnments
As useful as these techniques are, implementing them by hand is quite a complex task. Luckily, the team at hugging face has made implementing these technqiues easy. Stay tuned for my next blog where i teach you how to fine tune an open source large language model on a custom dataset using No-code library from hugging face!